
2026 AI landscape who benefits the most?

Hey everyone,
Here are UncoverAlpha’s 2026 top forecasts in the AI sector, including which companies stand to benefit most from these trends, and the biggest risk pressure points we are monitoring in the AI market for 2026.

The power in AI shifts from Nvidia to HBM suppliers and advanced packaging, as both bottlenecks will last longer than most people expect
While many recognize bottlenecks in both HBM and advanced packaging, we believe both will persist longer than expected. If we start with HBM.
Memory has historically always been an industry with big demand/supply cycles. Because of that, investors are very wary and are not fully »bought in« when a bottleneck in memory forms, as history shows that often times buying a memory company with a low P/E was a bad strategy (often times at the top of the cycle), and buying a memory company when the P/E was high was better. I am not saying this time is different, but I do believe we are still early in the HBM bottleneck cycle. As ASICs like Google TPUs and Amazon Tranium gain steam, their need for HBM is growing bigger and bigger, similar to Nvidia. 2026 is the year when we will also get a »full AI system« from AMD with their MI400 series. The success of TPUv7 in performance per cost, along with its delivery of a frontier model (Gemini), is driving many other companies to continue investing heavily in this space. HBM providers Micron, Samsung, and SK Hynix are receiving calls from the big tech companies seeking to secure their HBM supply. As HBM production is not increasing substantially, the bottleneck is getting tighter and tighter, where now Micron, Samsung, and SK Hynix can get better prices out of everyone, including Nvidia, as they don’t have only one big buyer anymore (Nvidia). HBM is already sold out for 2026.
According to Korean media outlets, big tech companies like Microsoft, Google, and Meta are practically stationed in Korea in an effort to plead to get any additional capacity from SK Hynix or Samsung. The problem escalated to the point that Google’s management dismissed the procurement personnel responsible, holding them accountable for creating supply-chain risk by failing to sign long-term agreements in advance. However, the HBM problem will even worsen as we transition to HBM4.
Nvidia’s Vera Rubin utilizes an 8-stack HBM4 configuration with a memory bandwidth of 22TB/s and a per-pin Fmax of around 10.7Gbps. AMD’s MI455X opts for a 12-stack HBM4 configuration (so even more than Vera Rubin), but at a lower bandwidth of 19.6TB/s, with a per-pin Fmax of around 6.4Gbps. AMD is betting on using less performant HBM4 and stacking more of it together. Nvidia’s Vera Rubin NVL72 will have 1.5x the HBM capacity of Blackwell and 2.8x HBM4 Bandwidth. But the Vera Rubin is just the appetizer when it comes to HBM capacity. In 2027, Nvidia plans to launch the Rubin Ultra with an enhanced HBM4 version, HBM4e, which will enable 12- or 16-high stacks, potentially reaching up to 1TB of memory per GPU (with an NVL576 system).
Keep in mind that ASICs, to remain competitive, will need to follow similar HBM patterns, which will worsen the crunch.
To top it all, because Nvidia can now sell its H200 into China, the demand that is from China for Nvidia’s H200 is putting additional pressure on memory makers, as H200 uses HBM3e. All three memory providers are building some new fabs for HBM4, but also reorganizing some HBM3 or even DDR4 and DDR5 memory lines into HBM4.
The problem is that HBM4 requires about 3x more wafer space than standard DRAM for the same amount of memory. As these manufacturers are reorganizing these product lines towards HBM, the supply of traditional RAM decreases, and now, even here, we have a bottleneck. The AI industry is in its early stages, and adoption isn’t at a point where we have humanoids, edge AI, AR smart glasses, or AVs in mass use, all of which require massive memory.
Moving now to the second huge bottleneck, advanced packaging.
The Advanced Packaging Bottleneck will get worse
Similar to the HBM bottleneck, I expect conditions will only worsen here. Since we moved to chiplets rather than monolithic SoC, much more advanced packaging is required. You can think of advanced packaging as stitching together different components of an AI accelerator to make them work as one. The goal is also to »stitch « them together as densely as possible to remove latency and energy losses. Advanced packaging is required for Nvidia GPUs, AMD GPUs, Google TPUs, Amazon Traniums, etc.
So naturally, with Nvidia GPU demand and now on top of that, ASICs programs getting scale the bottleneck is severe. The biggest and most important advanced packaging program is TSMC’s CoWoS.
According to Samsung Securities, TSMC’s CoWoS production capacity (converted to wafers) increased from 35,000 sheets per month in 2024 to about 70,000 sheets last year, and is expected to rise to about 110,000 sheets this year. However, evaluations indicate this remains insufficient. Given that TSMC’s CoWoS allocation to NVIDIA is approximately 55%, the calculation indicates that only 8.91 million “Blackwell” AI accelerators can be produced this year. This volume can support data centers with a maximum capacity of 18 gigawatts (GW), representing only 50% of global data center investment capacity this year. Samsung Securities analyzed, “There is a possibility that TSMC will not be able to meet even NVIDIA’s demand this year.”
Here are Goldman’s estimates for annual CoWoS. Even with capacity doubling in 2026 relative to 2025, it is still not enough to meet demand, as 2026 TSMC CoWoS capacity is already essentially sold out.
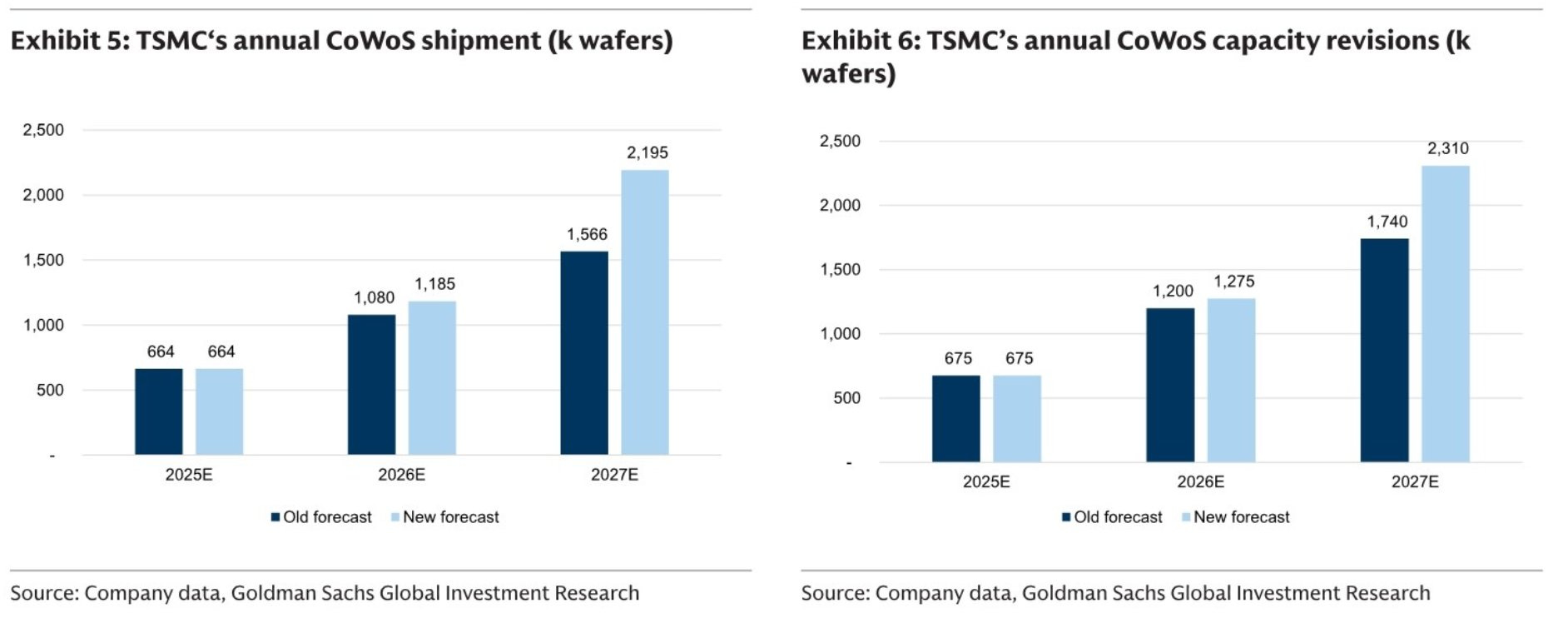
The crunch went so badly that there are now rumours that Meta has allocated some of its CoWoS from its ASIC chip to Google for its TPUs, as it appears Meta is preparing to start using Google TPUs.
The problem for all ASIC programs is that Nvidia is the dominant client and has most of the capacity reserved. If you are Google, Amazon, or Meta and your ASIC program can’t secure sufficient CoWoS capacity because Nvidia and AMD control most of the capacity, you are considering advanced packaging alternatives to CoWoS, as you don’t have time to wait. I believe this year, other players with advanced packaging will benefit (I will explain more in the company section of this article, including company names).
The transition to Co-Packaged Optics (CPO) from Pluggable Modules
2026 will also mark an important year of transition, as the industry shifts in networking from the pluggable era to CPO. We are seeing this transition as AI models grow in size, resulting in AI clusters with over 100k GPUs connected. With clusters of that size connected, you have a lot of pluggable transceivers. This is a problem as that amount of transceivers can consume 15-20% of the total power in an AI data center. Switching to optical providers can significantly reduce energy consumption, and the signal is more reliable.
The problem with CPO is that it requires advanced packaging, which is already a bottleneck in chip manufacturing. While TSMC is establishing a dedicated zone for this type of packaging through its COUPE platform, the bottleneck remains the same, and both affect each other. More on this in the company section, where I explain which companies benefit from the surge in interest in CPO.
Nvidia’s acquisition of Groq opens up a new path for additional AI chips for specific AI use-cases that open up the SRAM supply chain or combinations of SRAM and other memories
Nvidia’s acquisition of Groq is a big signal to the market, as I wrote in this article. With the move, Nvidia confirms that HBM and advanced packaging bottlenecks will likely persist and seeks to secure growth beyond them. This doesn’t mean that people will stop using HBM. Nvidia’s move signals that they expect the HBM bottleneck to be prevalent and long-lasting, so the industry will sell all available HBM over the coming period. At the same time, they need to consider other memory options to continue growing and address the compute gap.
Groq asset acquisition won’t impact core business, could spark something new
Jensen Huang
The main shift here is SRAM. You can fit an AI model on SRAM without HBM, but the model is then 100x smaller. This means SRAM use cases will be limited, but they do exist.
There are many workloads where latency matters a lot, but the model doesn’t need to be »god like« ( like serving an ad copy ). With agenic work, an agent could, based on the task, decide which high-quality model they need to answer, and if it’s an answer that can be answered by a fast, small model, they can use SRAM, and only if it needs more, they go to HBM.
Robotics also needs more SRAM, as it is low-latency, so you don’t need the big model here. And if you ask the humanoid a complex task, it can go to the cloud and use computing with HBM to get a more complex answer.
The point I am making is that we will see a mix of new memory variants emerge as everyone, including Nvidia, seeks ways to move beyond HBM. With this new trend, there is a new supply chain of companies that will benefit and have caught my attention; they will be shared in the company section of this report.
Google Gemini will continue to take market share from OpenAI
Since Gemini 3, Google has gained significant momentum in Gemini adoption. That momentum only accelerated after December 17 as Google launched Gemini 3 Flash. Gemini 3 Flash is very affordable and arguably the best current intelligence-per-cost model for many use cases. Not surprisingly, we received data from Similarweb showing that Gemini’s web market share increased to 21.5% from 13.7% three months ago and 5.7% 12 months ago. In the same period, OpenAI’s market share went from 86.7% 12 months ago to 64.5% today.
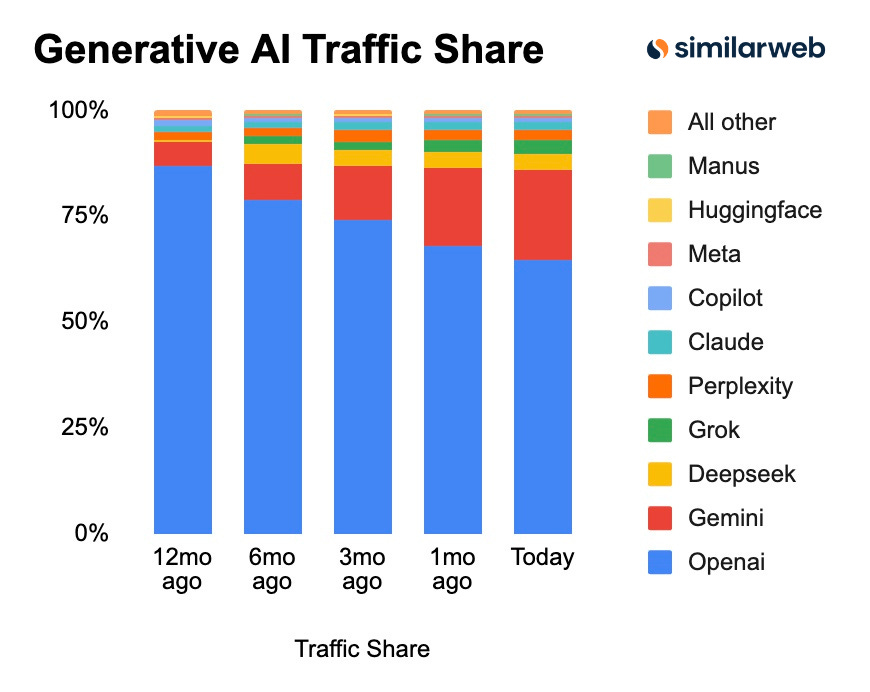
I expect Gemini to continue gaining market share, as the performance gap with ChatGPT over the past 2 years has now closed, and Gemini has taken the lead. Google’s product execution also took a significant upward shift in the fall of last year, as it appears management has learned that product shipment matters more than benchmark evaluations. On top of that, Google’s unique infrastructure advantage, derived from its TPU ASICs unit, gives it cost and scale advantages that it can leverage to put pricing pressure on the whole market. OpenAI acknowledged that they needed to allocate more compute for inference as the user base grew, and that they had to reallocate some of that capacity from their research (training) operations. Google’s DeepMind AI research unit also has an advantage over OpenAI: it is backed by a strong, Free-Cash-Flow-Generating business, so it is not dependent and doesn’t need to raise external capital.
The application layer of AI is becoming »investible«.
I expect in 2026 we will see renewed interest in companies that are characterized as the application layer of AI. Meta’s recent acquisition of Manus, a fast-growing agent AI company, is a strong signal to the market. While so far it was hard to invest in this layer, as the perception was always that »you are one core model upgrade away from being irrelevant, « things are changing. Manus and many other »AI wrapper« companies are showing that there is value in acquiring users and the user behavior patterns and data from their usage. The rise of methods such as fine-tuning, RAG, and RLHF can strengthen your moat on top of a foundation model, especially as we see frequent improvements in the post-training phase. I think this trend will accelerate in 2026, and opportunities in the application layer will finally emerge.
On top of the application layer, I also believe there will be more distribution deals, partnerships, or revenue M&A done. In distribution, the prime example is Snap partnering with Perplexity to offer Perplexity within Snapchat and, in return, receiving payment from Perplexity. I think the market will begin to view distribution companies more favorably. The most significant pressure on distribution deals will come from the broader ecosystem outside Google, as Google has the most distribution points available with Chrome, Gmail, Workspace, Maps, YouTube, and many others. I expect them to rely more heavily on those distribution points to support Gemini, which will put additional pressure on others.
Key market pressure points for me for both the AI market and macro
There are a few things for me that are important for this AI trend to sustain and continue, which I will be monitoring very closely in 2026. In terms of industry-specific, the number one is funding rounds for AI labs and startups, especially OpenAI and Anthropic. If any of those companies do not raise the amount of funds or at the valuation levels they set, I will view that as a very dangerous signal and may reduce significant exposure to the market. Currently, a lot of the ecosystem still hinges on those two companies to continue with their usage and spending.
The second thing is architectural modifications to how models are trained and served (inference). This ranges from model sizes to pre- and post-training methods, and includes memory requirements. If there is any significant change here, one needs to be very careful and reassess the factors, as it might shift needs and supply chains to others.
There is another pressure point at the macro level: the latest developments in Venezuela and their impact on the US-China relationship, especially regarding Taiwan. If anything happens there, even like a blockade or anything, everything changes.
Companies for 2026
Here are the companies I am invested in or on my watchlist that are aligned with these 2026 trends: