
AI compute: Nvidia’s Grip and AMD’s Chance

Hey everyone,
In this article, I am sharing my findings regarding Nvidia and AMD, as well as the advantages and weaknesses of both in terms of AI training and inference data center workloads. I will also share my view on the future demand and risks for both in this evolving AI landscape. For this article, I gathered multiple research reports and read & conducted interviews with former employees and industry insiders, including an interview with Jim Sangster, a former Nvidia director. The conversation with Jim is recorded and available to listen to for free on this LINK. I HIGHLY recommend listening to it as it was really packed with insights.
Now let's start with the article.

Nvidia and its moat
Over the last years, Nvidia has formed a moat around its business when it comes to AI workloads. It has a monopoly over AI training, but with new AI models skewing more towards reasoning, inference, becomes an important use-case as connecting multiple GPUs in a large cluster is so far the best way to serve both training as well as more complex inference (such as reasoning models). Nvidia's moat is formed from its full-stack service approach. Still today, many view Nvidia as a GPU provider, but it is far from that; instead, it offers a full-stack AI accelerator. If we peel down the most essential layers that form the stack, we can separate them into the following groups:
Hardware: GPU/AI accelerator
Software that optimizes the hardware (in Nvidia's case, that is CUDA and the software ecosystem that supports many libraries and integrations)
Networking with scale-up and scale-out, making it possible to connect the GPUs in a unified cluster that can handle more complex tasks.
In reality, the hardware component, which is the GPU, is the least interesting from a moat perspective for Nvidia because, for example, AMD GPUs often provide better performance characteristics on an individual GPU level. The real moat for Nvidia lies in the CUDA software and Nvidia's networking, which are the two areas I want to focus on.
Nvidia CUDA vs AMD ROCm
So starting with CUDA. The key thing when it comes to CUDA is that it has a significant head start, as it was developed by Nvidia several years ago. Since then, CUDA has evolved into a strong ecosystem, with great software libraries and a significant mindshare among engineers. Engineers are taught CUDA at a university level, so every engineer has been either taught or become familiar with CUDA. Besides being the best software optimization stack for GPUs, what is even harder for competitors to break down is the ecosystem that CUDA has built. Many industry experts share the same view that because CUDA knowledge is so entrenched in engineers, companies are not willing to switch to other software stacks, as they are not comfortable finding employees who know those other stacks. The numbers paint the picture. A Microsoft employee who works at Azure recently said this regarding CUDA/ROCm adoption:
»…within the NVIDIA developer program, and around 50,000 people had listed machine learning and CUDA as their skills on LinkedIn. I think we're talking to tens of thousands of people who have good proficiency in CUDA, specifically around training, computer vision, reinforcement learning, and GenAI. exact numbers, difficult to pinpoint, but you should be looking at somewhere around the 10,000-50,000 range.
ROCm, specifically from an AMD perspective, we have a lesser footprint. I think my number globally would be less than 5,000. If I look at LinkedIn, around 2,000 profiles we had found. I think you're talking about 1,000-2,000 people, max. I'm talking about engineers who have hands-on experience. I'm not talking about engineers who know theoretically about ROCm.«
source: AlphaSense
One of the key benefits of CUDA is that it continually improves your old Nvidia hardware over time with new software updates. Semianalysis has just conducted a benchmark comparison of running a training run on the H100 and the new Blackwell GB200 NVL72, and the results demonstrate why CUDA and its software improvements over time are so crucial, especially in AI training workloads. When they calculated the Total cost of ownership (TCO) of H100 compared to GB200 NVL72, the GB200 NVL72 TCO is 1.6x-1.7x higher than the H100 one, so the performance gains should be at least 1.6x-1.7x for it to make sense from an investment standpoint. GB200 NVL72 first shipment started in mid-February this year. By May 2025, the GB200 NVL72's performance per TCO had not surpassed that of the H100; however, by July, Semianalysis began to see the performance per TCO reach 1.5x that of the H100, which is close to the target range. That improvement is driven by software optimizations on CUDA for GB200 NVL72. By the end of the year, Semianalysis expects the performance per TCO to reach a 2.7x that of H100, making the GB200 NVL72 a clear choice for model training.
This shows how important the software CUDA layer is for chip performance, especially when it comes to training workloads. In terms of inference, the CUDA layer is less important, but other aspects of Nvidia's moat, such as scale-up and scale-out networking, remain key, especially for more complex inference workloads like reasoning models.
»In inference, the primary strength of people who can run inference on scale is the compute capacity. How much capacity do you have and what type of scale up and scale down services you have…Unlike training, where training is very technical. It's about doing math at a very precision level. It's about running training algorithms and running neural networks. That is where CUDA really shines. That is the key difference here in inference. You're not necessarily married to the CUDA level.«
Source: Microsoft Azure employee found on AlphaSense
That being said, AMD has made significant strides in developing ROCm over the past few months. Many industry experts are reporting that ROCm, with its recent update, has become much more stable.
Even AMD has stated that ROCm 7 achieves a 3.5x improvement in inference throughput performance over ROCm 6.
An Azure employee also emphasized AMD's recent kernel and compiler improvements:
»I think from a platform perspective is the compiler and the kernel improvement. AMD's HIP programming model is coming very close to CUDA in terms of portability and syntax. That's something which they need to continue to do so that people who are using CUDA can actually easily migrate to ROCm if they want to do.«
source: AlphaSense
So, ROCm is improving significantly, becoming more stable, and is now supporting a wider range of integrations and libraries. However, the biggest challenge it faces is the mindshare and ecosystem buildout that can't be fast-forwarded and will take years to develop. While I do see some clients, such as hyperscalers, joining the ROCm train sooner, as they are motivated to have an alternative for the rest of the ecosystem, AMD has to make significant performance leaps over Nvidia or build for years to develop a similar ecosystem.
Some industry experts suggest that CUDA converters could be a viable solution. However, those who have actually tried these converters claim that they convert the CUDA code at around 80%, while the remaining 20% must be done manually by kernel engineers, who, as you might expect, are not very inexpensive. In the end, the calculus for using converters from CUDA to, say, ROCm often doesn't make economic sense, as it is more costly due to kernel engineer costs than to simply go with Nvidia's products. Jim, the former Director at Nvidia, adds that the problem with converters is also that you have to stay on top of the stacks all the time, so you, as a customer relying on these converters to do their job in future updates, are risking it and bringing the problem of technical support to keep these converters relevant.
It is also interesting to note that while other companies are forming alliances to build alternatives to parts of Nvidia's full stack, no alliance has yet been formed to compete with CUDA. Everyone is developing based on their own stack. AMD has ROCm, Google's TPU runs on XLA (programmed by TensorFlow and JAX), Amazon Trainium has Neuron SDK, Meta MTIA has PyTorch/XLA backend, etc. Therefore, there is no broad coalition that would rally around a single stack to compete with CUDA.
AMD's decision to invest more heavily in ROCm is the right move, especially when its full rack solution, the MI400X, is released, as it is intended to be a competitive product for training workloads; there, the software optimization stack is crucial. So far, they have made good progress, and clients like the hyperscalers, with sufficient motivation, can start developing on ROCm. Still, the CUDA moat appears to be intact for now and remains a significant driver of Nvidia's adoption.
Networking
The next big moat of Nvidia is networking. With networking, we are referring to two segments: scale-up networking and scale-out networking. Scale-up networking enables GPUs in a single »box« to be connected to each other to form a single GPU server/node and make it as powerful as possible. Scale-out networking then enables these GPU nodes to connect to other GPU nodes and, together, form a large GPU cluster. For scale-up, Nvidia uses their proprietary NVLink and NVswitches, and for scale out, they use either InfiniBand (which they got from their Mellanox acquisition) or Ethernet (uses RDMA over Converged Ethernet) as a secondary »good enough« option.
To combat Nvidia's strong grip on the networking market for scale-up, a consortium of companies formed an alternative, known as the UALink consortium. The consortium consists of companies such as AMD, Amazon (AWS), Google, Intel, Meta, Microsoft, Cisco, Apple, Astera Labs, and many others. The goal is to establish an open standard for networking and an alternative to Nvidia, and make it so that you successfully connect GPUs and custom ASICs inside »on box«. While the consortium is relatively new, it is important for AMD, as one of its most significant disadvantages compared to Nvidia is networking. And networking matters not only for training AI workloads but also for inference. As inference becomes more complex with reasoning models, having good scale-up and scale-out is key. AMD has learned from its mistake on the MI300X in deploying an Infinity Fabric that was much worse than NVLink. They have also recognized that they lack the hardware talent to execute on an NVSwitch equivalent, and at the same time, to solve this challenge, they want to support every alternative available. That is why they have flexible I/O lanes. These flexible I/O lanes enable AMD to support different standards (Infinity Fabric, PCIe, UAlink, etc.). It is clear that AMD desperately wants a performant alternative to NVLink.
While the UALink consortium is still young, it has already had a big setback. At first, Broadcom was one of the key companies involved, but later backed off because they decided to develop their own proprietary alternative called SUE. This was a significant setback, as AMD now has to rely on Astera Labs and Marvell to produce the UALink Switches, which won't be ready until 2027. That is why we can see that while AMD's MI400x has UALink Serdes, it is not a complete UALink scale-up network; instead, AMD had to go with Broadcom's Tomahawk 6 Ethernet switches, and that is why it's named as »UALink over Ethernet«. Despite this setback on the scale-up side, based on AMD's specifications, MI400x looks to be very competitive.
Nvidia is not just watching this development, though, as one month after UALink 1.0 was announced (April 8th), they announced NVLink Fusion, which, on paper, opens up the NVLink ecosystem. This is a big step for Nvidia, as a Former high-ranking Nvidia employee explained how challenging it was to implement this step internally, as Meta wanted to use NVLinks for their MTIA back when he was working there, and the answer from Nvidia was a firm »NO«.
However, there is a catch with NVLink Fusion. The former Nvidia employee mentions that Nvidia will not provide public specs; instead, they only provide the soft IP to specific vendors, but the specs remain proprietary. To implement NVLink Fusion in your accelerator, such as a TPU or MTIA, you still need to integrate both NVLink and Nvidia's C2C (chip-to-chip). Part of it remains proprietary to Nvidia as the NVLink IP communicates with the chip in a proprietary manner. With it, Nvidia forces you to use their C2C. Clients are now realizing this, as the former Nvidia employee mentions that they are concerned this will further entrench them in the Nvidia ecosystem, even with their custom ASICs, so UALink remains the alternative.
A key point for both Nvidia and UALink is the role of Astera Labs now that Broadcom has taken its own route. The consortium now depends on Astera Labs to provide the switches. At the same time, I don't view it as a coincidence that Nvidia, in its NVLink Fusion announcements, listed the following companies as the first partners to adopt the technology: MediaTek, Marvell, Alchip Technologies, Astera Labs, Synopsys, and Cadence. Nvidia knows that Astera Labs is now the key piece in the consortium and might be motivated to give them more orders of NVLink Fusion, where they limit their capabilities to serve the UALink consortium. Time will tell.
On the scale-out part, the alternative to Nvidia's InfiniBand is Ethernet with RDMA (RoCE). Nvidia also supports this alternative, but as a secondary, less performant option to their proprietary InfiniBand solution. Nvidia even has a Spectrum X Ethernet platform, as they have Spectrum switches from their Mellanox acquisition. In addition to Ethernet with RDMA, a consortium known as the Ultra Ethernet Consortium (UEC) has also been formed. It was formed by companies like AMD, Broadcom, Arista Networks, Cisco, Intel, Meta, Microsoft, Oracle, and many others. The goal again is to make an extension to Ethernet and reduce its weaknesses vs InfiniBand. Many hyperscalers also support Ethernet because it is cost-effective, already widely deployed in data centers, and has multiple vendors (Broadcom, Cisco, Arista, Marvell). Ethernet with RDMA has gained significant traction, as both hyperscalers and companies like Meta are willing to adopt it to reduce Nvidia's grip. While Ethernet networking still lags behind InfiniBand, many industry insiders agree that the performance gap has narrowed significantly in recent years. Seminanalysis confirmed this recently in one of their reports, saying that »Even Nvidia recognizes the dominance of Ethernet and with the Blackwell generation, Spectrum-X Ethernet is out shipping their Quantum InfiniBand by a large amount«.
To summarize, when it comes to networking, so far, the scale-out consortium UEC appears to be progressing well. For AMD, the key thing is for UEC to continue its progress, while on the scale-up, there are more challenges. If UALink doesn't ship and start progressing faster, they still have a solution with Broadcom with SUE, but again, that will mean Broadcom will be the only viable alternative out there for scale-up, which gives them a lot of power.
HBM design a possible next battlefield for the »full stack« offering of Nvidia/AMD?
While we did cover the two most critical layers with CUDA and networking, there appears to be one more that is just starting to form, and it is HBM. HBM is one of the key pieces when it comes to AI accelerators. Its importance is only growing with bigger and more complex models. SK Hynix and Micron primarily supply HBM3, although Samsung is expected to finalize its certification process and join them as well. A key change is coming soon as we transition to HBM4 memory. Here, the base die will move to a modern logic process, which means SK Hynix and Micron can't manufacture this internally but must outsource it to TSMC. Memory providers will also have to partner with logic design companies or IP vendors to help with these designs. This opens up a window where custom HBM implementations will happen. What that means is that both Nvidia and AMD will release their custom HBM4 implementations. This process again opens up a door where one company can achieve competitive advantages as the process becomes more complex and customizable. For AMD and Nvidia, this is a key step where again they have to be on top of it, avoid missing out, and remain competitive. This also means that the life for custom ASICs is becoming even harder and more complex, as they will have to handle that part as well. The biggest chances are that they will do so by partnering with one of the existing memory providers and choosing some default plans.
AMD's chances to compete with Nvidia?
First, let's start with some of the problems that AMD has compared to Nvidia:
AMD MI350X series shipments have just started, so those haven't shown up significantly in their Q2 numbers yet. Most of the »AI GPU sales« in the Q2 report were attributed to their MI300 or MI325X, which was a product that wasn't launched at the right time, as AMD wanted to ship it in Q3 2024 the same quarter as Nvidia H200 started shipping, but due to delays, they had to start shipping it in volumes only in Q2 2025. However, this window indicates that the MI325X was competing with Nvidia's B200 orders, which is a significantly better chip than the H200.
AMD doesn't have a strong presence with neocloud players, as even though their GPUs are cheaper than Nvidia's, the costs of renting AMD GPUs for clients on the cloud are higher than that of Nvidia because there are not enough of AMD instances out there, which results in those who are being priced higher than Nvidia GPU instances.
ROCm is a far less developed software layer and has a much smaller ecosystem compared to Nvidia. Until recently, it also had many stability issues.
Networking is/was also a problem for AMD, as we already discussed; they are now addressing those challenges in new generations of their chips with consortium and outside partners.
AMD doesn't have a full rack-scale solution out yet. MI400X is expected to be the first one
Now, some of the positive developments for AMD:
The latest version of ROCm has become much more stable, and AMD is investing heavily in its ROCm stack.
AMD addresses its lack of presence with Neoclouds, now trying to mimic Nvidia's approach of selling its GPUs and then renting them back from Neoclouds, making more capacity available, and with it helping to reduce the prices for their instances for customers.
Most of the big Nvidia clients are looking for an alternative to Nvidia as they all »feel« the Nvidia grip. Therefore, the motivation to try other options, especially those from AMD, is high, despite some of the weaknesses that AMD has compared to Nvidia.
Nvidia's launch of its Project Lepton, which is a compute orchestration platform between cloud providers, is angering a lot of neoclouds as well as hyperscalers, as it is an effort to commoditize the cloud industry. Jim, the Former Nvidia director, in our talk mentioned that for hyperscalers, the moat/lock-in is still the data and the software apps and tools that you, as a customer, use and have on these hyperscalers, but for neoclouds, that argument doesn't hold, as they are more just a compute provider. With Neoclouds angered, the chances of them doing deals with AMD have increased.
Inference workloads are becoming more and more critical. Inference is where the chances of AMD's success are higher.
The recent surge in inference will probably cause Nvidia's chips, especially the GB200, to be sold out soon. For everyone besides Google (that has mature TPUs), AMD is the best second option. Furthermore, the limited leap forward of GPT5 suggests that GB200 NVL72 clusters will be required for the next significant model advancements in training (GPT5 was trained on H100 and H200), which will lead to an additional shortage of GB200 and GB300.
The MI350 chip and MI400X look promising on a few levels
MI350 series and MI400x
With its new MI350X series, AMD is releasing two versions: the MI350X and the MI355X. The MI350X is a 1,000W air-cooled version, while the MI355X supports both air and liquid cooling but is a 1,400W version. On paper, the MI355x is 10% faster, but it consumes 1.4x more power (in practice, we will see the real performance, though).
I actually think the » air-cooled « market segment is something where AMD can get a lot of traction before its MI400X release, as many customers are very limited on liquid-cooled data centers and are increasingly adopting NVDA's GB200 NVL72 in them (which require liquid cooling). Numerous air-cooled data centers could be harnessed with the MI350 series, competing directly with NVDA's HGX B200 NVL8 and HGX B300 NVL8. That probably means the MI350 series will be used most for inference by smaller LLMs and less so by frontier reasoning ones, where GB200 NVL72 will dominate.
The MI355 appears to offer a significant total cost of ownership (TCO) advantage over Nvidia’s B200/ B300 series. Its all-in capital cost per chip is 45% lower than that of Nvidia’s B200 HGX, primarily due to significantly lower chip pricing and lower transceiver and switch pricing resulting from not relying solely on Nvidia-supplied components.
So far, the interest from clients, from what I've heard, is quite strong and AMD’s CEO mentioned that on their last earnings call. Also worth noting is that OpenAI's CEO was on stage at AMD's event. Oracle has already announced that it will deploy 30,000 MI355Xs, and AWS was a sponsor at AMD's AI event. We also know already that Meta is internally using some AMD for their inference cases. Lisa Su even said on their earnings call that they are ramping production faster than expected for the MI350 series.
All in all, the MI350 and MI355, in my view, are the products that will gain the most traction in AI workloads for AMD, especially as mentioned earlier, as a great way to use air-cooled data centers. It is still not a rack-scale solution, so for more complex reasoning inference, Nvidia's GB200 NVL72 will still be the dominant choice.
Turning now to MI400x. Based on the specs, the MI400x should be very competitive with Nvidia's Rubin, which is expected to be released at a similar time. However, considering TCOs and power consumption, it will be competitive but won't be significantly cheaper than Nvidia's Rubin, which is surprising. The power consumption might be an issue for AMD, as most customers are seeking energy-efficient solutions, as they are limited by power availability. The cost of power itself is not a problem, but building the infrastructure to support it is. Then, when MI400X comes out, the usage of power might be one of the most critical metrics. The positive aspect of MI400X is that it is the first true rack-scale solution for AMD, and clients will have a serious alternative to Nvidia at that point.
Nvidia is still king even when it comes to inference
Inference is becoming one of the most important workloads, as it is far larger than the training workloads that have dominated thus far. As Jim, the Former Director at Nvidia, said, it was once thought that training would be done on a massive cluster and that inference would be performed on a number of smaller devices. The old thinking was that inference would be 10x the size of training, but with reasoning models this has changed to an order of magnitude bigger difference (some even say 1:100).
With reasoning models, inference underwent significant changes. Jim provided an example of comparing two models: a traditional one and a reasoning one, both for the same task (optimizing seating for a wedding). The reasoning model provided a better answer, but here is the catch: the traditional model generated 449 tokens to produce the answer, while the reasoning model generated 8,595 tokens (20x more tokens). The reasoning model also hit the cluster 150x more than the traditional model. This shows that, even for inference when it comes to reasoning models, we will now need big clusters, where Nvidia shines.
The catch is that reasoning models, especially now with GPT-5 and its routing feature, will be used even more, as most ChatGPT free users haven't used them until now. To add to that, AI agents only add to more reasoning model use-cases, even for inference, when it comes to reasoning models,
Altman even shared some data to back that up:
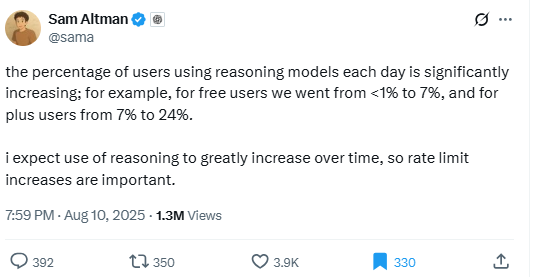
Within just a few days of the GPT-5 introduction, the usage of reasoning models increased by more than 7x for free users and 3x for paid users. This, of course, is causing a rapid surge in the need for compute, especially cluster-like compute, such as Nvidia's GB200 NVL72. So Altman's comments later are not a surprise, as he said that they are out of GPUs, had a big GPU crunch, and that you should expect OpenAI to spend trillions of dollars on data center construction. Just a few days ago, OpenAI's CFO appeared on CNBC and stated that we are in the very early stages of the data center and compute buildout, comparing it to the construction of railroads and energy infrastructure, and discussed the internet as a smaller-scale buildout.
While there will still be on-edge inference use-cases in robotics and other forms, when it comes to data center and running front-tier models, which, as of right now, look as though they will be very dominated by reasoning models, you will need a cluster-like system to handle the inference. Nvidia's GB200 NVL72, with its 72 GPUs, is the ideal system for running that inference right now.
SemiAnalysis in one of their reports tested inference of Llama 70B (so not a small model), and the results of GB200 with TensorRT LLM blow every other GPU out of the park in terms of tokens generated:
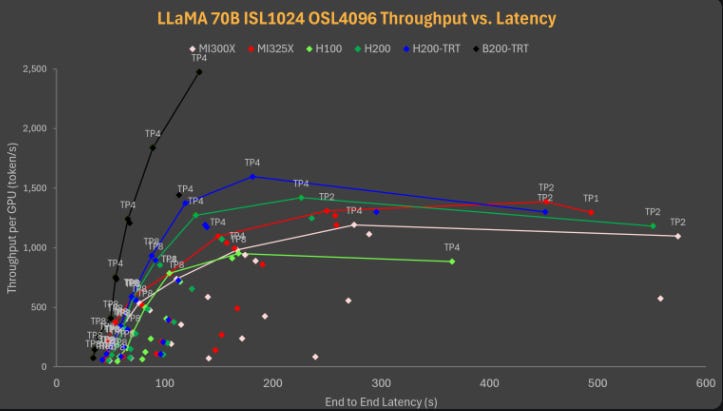
This again positions Nvidia very well, as they are leaders in both scale-up and scale-out networking.
There is room for AMD to get some inference workloads from smaller models or ex-reasoning models, at least until their MI400X offerings are available and the networking issues are fully resolved.
Why would clients upgrade their old Nvidia cluster for new ones?
One key element that I came across via research answered my question of why Nvidia clients would upgrade their older versions of Nvidia servers to newer ones. The fact that CUDA improves the performance of older hardware over time adds to the argument that you might be well off with the older versions. While an obvious answer would be getting better performances from new servers, that answer is only partial. The real motivation for this is the limited amount of energy that clients have available for data centers, and here we reach a key point. Jim, the former Nvidia director, explained it well during our discussion:
»When you have a data center or build a data center, you work with a power company, you have a power footprint, that power footprint is limited, you can't just call and say Hey, I need 10% more. If we compare current generations and future generations of Nvidia servers limited to 100MW of data center power, how many tokens per second can I generate? H100s limited to 100MW of data center power, generate 300M tokens/seconds, GB200s NVL72 with the same 100MW limitation generate 12B tokens/second. That is the staggering change of moving forward.«
Jim is not the only one thinking about energy efficiencies, driving upgrades. ARM's CEO recently said the following: »The Grace Blackwell platform is 25x more efficient on power than the Hopper with x86.«
So, the real main selling point of Nvidia is not necessarily more performance; it comes down to less energy consumption, which in turn means more tokens per second. There is a reason why Nvidia introduced GB300 NVL72 on social media as: »Our latest platform, the Nvidia GB300 NVL72, reduces peak grid demand by up to 30% - smoothing energy spikes, optimizing power use, boosting compute density and cutting operating costs.«
Overall, the leaps of performance and energy consumption that Nvidia has made with its Blackwell infrastructure are, in my view, enough to entice its customer base to upgrade. For training GB200 NVL72 with continuous CUDA improvements, it has just hit thresholds where, even from a cost perspective, it makes sense for clients to upgrade, and now even on complex inference like reasoning models, which are on the rise, GB200 NVL72 is the best inference solution out there. The fact that we also see limited leaps in performance progress from GPT5, which was trained on H100 and H200, suggests that AI research labs will need to leverage the GB200 NVL72 to create the next frontier models with better performance.
I expect Nvidia's Blackwell servers to be sold out for the foreseeable future.
Risks to the demand story for Nvidia and AMD
When it comes to the risks to AI data center demand for both Nvidia and AMD, there are three key risks that I look at:
AI CapEx runs out of Capital
Scaling laws ceiling & New significant architectural change in inferencing AI models
Data center limitations and energy equipment shortage
If we take a deeper look at that, first starting with AI CapEx running out of capital. First of all, the demand for data center GPUs is real and doesn't appear to be slowing down anytime soon. An OpenAI employee recently shared that OpenAI has 15x its compute from 2024 to the present. We have already mentioned the recent statements from OpenAI's CEO & CFO about experiencing a significant GPU crunch and being out of GPUs. However, it's not just OpenAI; Anthropic is also experiencing a surge in demand for coding AI assistants. Additionally, Meta signed a $10 billion cloud compute deal with Google Cloud just yesterday, despite investing over $70 billion in data center capital expenditures. From the earnings of all the hyperscalers, including Google, Amazon, Microsoft, and Oracle, we heard the same thing: demand is outstripping supply; we need more data centers and more compute.
Despite that, we have to acknowledge the concentration of clients for Nvidia and AMD. Dylan Patel recently mentioned on a podcast that OpenAI and Anthropic account for around 30% of Nvidia's chip demand. The other 1/3 is going to ad-based companies like Meta, ByteDance & the rest is non-economic providers.
We also can't go past the fact that the concentration of customers for Nvidia will continue to be high, as many enterprises that have on-prem infrastructure are starting to figure out that the compute they need is really expensive to buy and secondly more important that their data centers are not ready to be AI data centers primarily as they are not liquid cooled data centers. As we discussed today, the new Nvidia servers are liquid-cooled, and most data centers outside of the hyperscalers do not have liquid-cooled facilities. This will accelerate the process of migrating from on-prem to cloud for even those enterprises that have been hesitant to do so for many years. The complexity of running an AI data center with a severe thermal load is also a magnitude harder than running a traditional data center.
As cloud providers report high demand spikes, a significant portion of that comes from two companies: OpenAI and Anthropic. As long as these two companies, and I would add xAI at this point, can continue to raise new rounds and gather capital, the demand from them will continue to rise. Just yesterday, Anthropic was planning to raise $5 billion at a $170 billion valuation. Due to high investor interest, they decided to increase the raise to $10 billion. From this move, you can see that all of that cash is going towards compute as they will need a lot more to continue growing on this trajectory. OpenAI is not only looking to raise the next rounds at +$500B valuations, but it is also exploring debt instruments to gather even more capital. The fact is that while these companies have over $10 billion in revenues, they still require significantly more compute to develop the next frontier model, as well as to serve inference for the usage spikes they are experiencing (OpenAI now has over 700 million monthly active users). As long as we see these companies continue to gather capital without problems, the demand for Nvidia and AMD will be there.
The other part of the demand comes from Meta and other Big Tech companies that have core businesses that generate a ton of FCF. Here, the trajectory of that CapEx growth will start to hit some limitations. We are now in the $70-$90B range, given how core businesses are growing. I think we may have a 30-40% growth possible before we start to see these companies come under pressure from their shareholders for the massive investments they are making.
Now the third part of demand that is really starting to take off and is a big question mark, which we might get some clarity on the size of it, is Sovereign. These are countries or companies connected to countries that are building their own data centers as they understand the importance of AI, for security and independence. This demand is coming from the Middle East countries, Europe, and many others. We are still early with Sovereigns, so that might become a significant driver of AI compute demand in the coming quarters and years.
Moving on to the second risk, which is »Scaling laws ceiling & New significant architectural change in inferencing AI models«. Regarding scaling laws hitting a wall, this is a topic on which a lot has already been written, so I don't want to delve too deeply into the details. The key thing to follow is the progress of the new frontier model. GPT5's less impressive performance is something to keep an eye on, especially as we see what comes from Google's Gemini, xAI's Grok, and others. So far, I don't think we are at that wall yet, as OpenAI's problems seem to be siloed to them. With their rapid user growth, it appears that they had to make a hard compromise: give compute to inference users or give compute to training and limit current usage. Because GPT5 didn't really get the amount of compute that it could get. OpenAI's success in terms of usage of their products is now hindering its new model development, as there simply isn't enough compute available to serve both. It is also important to note that we already mentioned that GPT5 was trained on H100 and H200, not GB200. Nonetheless, if we see small model progresses from the other frontier labs in the next few months, that is a sign to watch out for.
The other risk that I mentioned was a significant architectural change in inference AI models. Here, I am not talking about a DeepSeek-type change, where we obtain more efficient models that still require GPUs. This is positive for Nvidia/AMD, as more efficient models unlock additional usage, as we have seen with DeepSeek. The change that would be concerning for these companies is if we would get tech breakthroughs that would allow CPUs to effectively inference even the frontier reasoning models. So far there is nothing to point to that.
The last risks on my list are Data center limitations and energy equipment shortage. This is a risk that will slow down potential growth but not stop it, as we can already see that providers like Nvidia understand the importance of power consumption on these AI servers, with GB300 and many others. Given the constraints of their customers, Nvidia and AMD might find a niche, as we previously discussed, offering significant performance per watt improvements every year, which could spark a major upgrade cycle.
With all of these mentioned risks, we still need to acknowledge that this article focuses on AI data center compute; we haven't covered edge compute, robotics, AVs, which are new emerging markets.
Summary
Nvidia continues to be the king when it comes to training as well as inference. For inference, GB200 NVL72 is the superior solution, especially when it comes to big reasoning models. Despite that, AMD has a chance to find its spot in the sun. AMD ROCm is progressing well in becoming more stable, and most Nvidia customers are looking for a serious alternative, especially with Nvidia's Lepton project. As the complexity of the full-stack AI server increases with HBM4 and other components, ASIC alternatives will become even more challenging to manage. Therefore, leaning on AMD as the second choice is a natural one. AMD's air-cooled MI350X series also appears to be a promising product that could be widely utilized, as numerous air-cooled data centers are waiting to be leveraged more effectively for AI workloads. AMD is also finally establishing better relationships, and the sell-and-lease-back model with Neoclouds will make its cloud instances more affordable, which should attract more usage.
There are no signs of demand for GPUs cooling down anytime soon; on the contrary, it is accelerating, with inference now becoming a critical factor. Nvidia reports its earnings in a few days. I expect strong numbers, as GB200 represents a significant leap forward, especially in inference, compared to H100 and H200. This is the perfect timing, as inference is gaining momentum. The amount of Blackwells sold will, in my view, surprise even the most bullish analysts in the next few months.
As always, I hope you found this article valuable. I would appreciate it if you could share it with people you know who might find it interesting. I also invite you to become a paid subscriber, as paid subscribers get additional articles covering both big tech companies in more detail, as well as mid-cap and small-cap companies that I find interesting.
Thank you!
Disclaimer:
I own Meta (META), Google (GOOGL), Amazon (AMZN), Microsoft (MSFT), Nvidia (NVDA), AMD (AMD), and TSMC (TSM) stock.
Nothing contained in this website and newsletter should be understood as investment or financial advice. All investment strategies and investments involve the risk of loss. Past performance does not guarantee future results. Everything written and expressed in this newsletter is only the writer's opinion and should not be considered investment advice. Before investing in anything, know your risk profile and if needed, consult a professional. Nothing on this site should ever be considered advice, research, or an invitation to buy or sell any securities.
Great piece Richard! I would love to hear your thoughts on another risk about whether there is enough AI revenue to support the huge capex investments required highlighted in this article - https://pracap.com/global-crossing-reborn/
Thanks for sharing