
DeepSeek and the ramification on the AI industry: winners and losers?

Hi everyone,
I wanted to share my thoughts on the recent breakthrough of the Chinese R1 DeepSeek LLM model and the repercussions that this breakthrough will have on the industry. Like last year, when OpenAI's reasoning model o1 came out, I wrote about the significant industry change, the shift from pre-training to inference. I view the R1 DeepSeek moment as another significant breakthrough in the industry that will shuffle the cards once again. So, let’s get to it.

Who is DeepSeek?
The DeepSeek team was founded in 2023 by Liang Wenfeng, a Chinese entrepreneur. They are an LLM model provider that open-sources their models. The team is supposed to have under 200 employees. They are highly technical people, mostly from Wenfeng's quant trading hedge fund.
While some people question these facts and their limited amount of computing resources (GPUs), the claims are that they trained the R1 model for $6M of compute training on older Nvidia hardware because of U.S. chip export restrictions. Scale AI CEO Alexandr Wang says DeepSeek is misrepresenting its claims about only using 2,048 Nvidia GPUs; said the number is about 50,000. He says the main reason for doing so is because they don’t want to admit that they are getting the chips despite the U.S. restriction.
While nobody can really know for sure based on the technical paper that they released about their newest models, V3 and R1, which I will cover more in-depth, it seems plausible that they drastically reduced the need for training compute. In any case, my focus on this write-up is the breakthroughs they revealed in the research paper and how this will change the industry as other players adopt these changes.
In general, after going through this, the view is that constraints are really the mother of invention. R1 has some minor model performance improvements compared to most frontier current models, but the biggest innovations are in the training and inference size and, with it, the costs to train and run these models.
For those less technically equipped, the most simple way to understand these changes is that DeepSeek took OpenAI's frontier model and used it as a teacher for their model. With this, they distilled the model into a smaller one while keeping almost all of its performance intact. Because the model is smaller, and with some other innovations, they drastically lowered the cost of training and running it.
Now let's dive into the most important breakthroughs that the DeepSeek team showed the industry:
A new training method that allows them to use 8-bit floating point numbers instead of 32-bit numbers
Probably one of the most significant breakthroughs of the paper was using 8-bit floating point numbers for training instead of the »industry standard« 32-bit numbers. The tradeoff here is that 8-bit sacrifices some of the precision but saves a lot of memory. However, DeepSeek developed its own system, which broke numbers into small tiles and blocks and used high calculations in the network at key points. By doing so, it seems they didn't compromise much of the performance, but they saved a ton of memory. Memory is crucial in the training process; it is also one of the main reasons why Nvidia GPUs dominate the training process of LLMs. When training an LLM, you must use multiple GPUs that communicate with each other, as well as HBM memory outside of the chip. One of the reasons for Nvidia's strong moat is that they are the best in this communication between GPUs and the memory, compared to other GPU providers like AMD.
Predicting what tokens the model would activate and only trained these tokens.
One of their important innovations was around Mutli-head Latent Attention (MLA). Specifically, here, they focused on the load-balancing aspects. To put it as simple and nontechnical as possible, the key here is that the model doesn't always need to store every single parameter count that it has but only focuses on the important ones. They did this without any performance degradation that usually comes with load balancing. They basically route the inference requests to a smaller model that is most able to answer the query or solve the task. In the big model, you have small experts, like accounting experts, coders, legal, etc., and they route the question/task to the »expert« who is most likely to answer or solve the task best.
They also made many other smaller changes, like compressing the KV cache, which means much cheaper inference, and, of course, used reinforcement learning to replicate the o1 OpenAI model.
I encourage anyone interested to lead the research paper.
The results of all of this?
Because of these changes, DeepSeek's API, as reported by some users, is 95% less expensive per token than OpenAI's o1 model while having similar performance. The DeepSeek model is supposed to be 45x more efficient on the training side than other models.
What does this mean for the AI industry?
Model providers
This is definitely a big shock for LLM model providers, especially closed-end providers whose business (at least so far) relies on selling access to the most capable LLM models, such as OpenAI and Anthropic. The problem gets bigger because DeepSeek is an open-source model that anyone can use. If it were closed-end, there would always be the argument that U.S. companies do not want to share their data with Chinese companies.
It also means that they will have to move even faster with innovation and newer models, which puts the already fast-paced AI race into another gear as it is clear that the open-source community will now get another boost playing with DeepSeek's model, similar to how Meta's open-source Llama opened the open-source floodgates.
At the same time, this open-source model allows OpenAI, Anthropic, and others to adopt the innovations they brought and use them in their future models.
To this point, OpenAI and Anthropic have been doing pretty well, especially since OpenAI with ChatGPT has captured brand value. For many months, they have been among the top-down loaded apps on the App Stores. While the professional community often discusses new breakthroughs like DeepSeek and others, the mainstream community still mainly knows and acknowledges ChatGPT as the app they use.
The adoption of both ChatGPT and, even more so, Anthropic has been on a very good rise lately. This data shows the percentage of companies mentioning ChatGPT or Anthropic as needed in a job opening. We can see real momentum, especially in Anthropic, who has gained a lot of attention with the AI models coding skills:
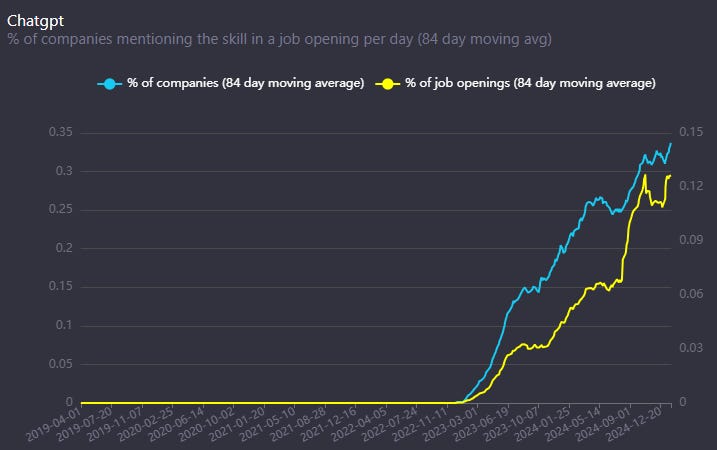

So, there is no question that both OpenAI and Anthropic are building brand value. OpenAI seems to be strong on both fronts (consumer and business), and Anthropic appears to be gaining more ground in businesses. To add here I expect Anthropic to continue to focus on business as the motivations of their biggest investor AWS (Amazon) is probably most strong in winning enterprise customers and their cloud workloads.
However, the problem that emerged yesterday is that DeepSeek's app (which uses their LLM model) is now the top downloaded app on the iOS App Store.

This could be a sign of current momentum or screwed tactics by Chinese companies to get to the top charts (in the last months, we have seen many companies very unknown before reaching the top ios charts for a short period). Still, the fact remains that if DeepSeek stays on the top downloaded charts for the following weeks, OpenAI and others will have to be very careful and focus a lot more on innovation on the user interface and use-case side.
Some users like Garry, the CEO of Ycombinator, are already mentioning some benefits of using DeepSeek's app interface, such as being more transparent with reasoning and chain of thoughts than for example OpenAI:

To summarize, for closed-end model providers, there are benefits from DeepSeek's release because they can optimize their cost structure to make even more capable AI models. I don't expect them to lift their foot off the gas when it comes to compute and memory, as while DeepSeek shows cost savings, having more compute and more memory still results in better models.
The problem that closed-end LLM providers have is that lowering pricing is inevitable on their revenue side, and with it, their break-even points feel even more down the line. Getting new massive funding rounds might get just a tad harder, as the questions about the long-term moats of these model providers are now even bigger, with open-source commoditizing the landscape. The problem now also becomes that releasing your front-tier model can become more risky, as all of that R&D and computing that you put in that model can then be taken advantage of by another company distilling your model and using it as a »teacher« for their model with a fraction of that cost. The closed-end model providers will have to start figuring out a different business strategy if not for anything else.
What about semiconductors? What about the elephant in the room- Nvidia?
When it comes to semis, there are a few things to consider. LLM providers will implement the DeepSeek innovation into their models and, with existing infrastructure, release newer frontier versions of models. The chances of achieving AGI in the next few years have increased with this. This also means that we get more capable models at low costs, increasing AI adoption, which was often hindered by computing and infrastructure. For example, if o1-pro were a free or $10/month subscription, consumers and companies would expand their use cases and increase adoption. The fact that OpenAI and others also limited the number of queries/tokens is not because that would be the choice of the LLM provider or business model but because of the high cost of computing they have to pay to run these models.
To return to semis. This means that adoption accelerates, translating into increasing the number of chips needed, as adoptions shift toward inference use cases driven by user usage. This is for example benefical for someone like Taiwan Semiconductor as they are not dependant on training workloads, they benefit from both training as well as inference workloads, so getting more orders from the Groq's, SambaSystems, Cerebras, hyperscaler custom ASICs is something which should be expected. On the other side, for Nvidia, the demand for their high-end training systems will remain high, but the question they will have to face is the margin. While we knew, and what I wrote about many times before in my previous articles, was that long-term, it is hard to image Nvidia's long-term margin being sustainable, now even in the short term, we might get to a gap of demand where LLM providers see that with existing infra they can achieve new model improvements, but have less of a need for Nvida high-performance chips in the current year as they are constrained with power but have enough compute capacity in the short-term. However, that argument may be questionable as newer versions of Nvidia's chips are much more energy efficient. That argument alone can be a catalyst for companies moving over to Nvidia's newer chips.
But what I think is clear is that the market movement to inference is now speeding up. And Nvidia's moat in the inference market is much lower than in the training one.
As this semiconductor expert mentions:
»There are known challenges from NVIDIA specific to inference. I could get probably too technical in trying to explain the challenges, but it would be hard for even NVIDIA to counteract the points that everyone would make in terms of their challenges in using a GPU or graphics processor architecture for inference of large language models. It's not the optimal platform for that use case.
The reason NVIDIA has had such incredible share is because nearly everyone used NVIDIA in training the models, and rather than go and buying another system, learning new software, and all of that to just run inference, everyone's tried to just make use of the hardware they already have in place that they've been using for training, and now just use that same system for inference.«
source: AlphaSense
As the market speeds forward to inference, the number of chips needed will increase significantly, but the margins on those chips will be much lower. Therefore, Nvidia, with more competition, will also have to adapt to that margin profile.
On the other hand, for Taiwan Semiconductor, nothing changes, as the ARM CEO recently mentioned on a podcast: They are the only game in town when it comes to 2nm and 3nm fabs. For TSM, the transition to inference is even beneficial as now more customers are competing for orders instead of having one strong customer in training who can become a significant part of your revenue and, with it, risk as well.
The market memory is another important part of the semi chain when it comes to AI workloads. As we have seen, one of the key improvements of DeepSeek's model was to optimize and reduce the amount of memory you need for a workload. Here, we have to understand a few things. HBM is a bottleneck right now; HBM orders are sold out for this year, and I don't expect this to change. The equation of more computing and more memory still equals a better model. With it being a bottleneck, I also don't expect pricing pressures to happen here, at least not in the next few years.
With HBM, some might argue that ASICs can use SRAM instead of HBM. A semiconductor expert and former Groq employee explains it well. SRAM is basically the memory inside the chip. The problem is that you can only put so much SRAM memory into a single chip as you are constrained by space. In the end, you must add HBM. For newer and newer models, the same scaling parameters will apply. Compute, data, memory.
But the memory players could get a tailwind from DeepSeek changes. This can finally cause the PC and smartphone upgrade cycle that all have been waiting for, with the demand for traditional memory finally having a turning point. The reason is that now, with smaller, highly capable distilled models, consumers and companies can use them and run them locally to get some benefits. For this, they still need to upgrade their hardware, so traditional memory might get a boost. These locally run models won't be frontier as the industry will evolve even faster, but they might be good enough for certain use cases for which businesses or consumers want to fill the need.
Cloud providers
Moving to the cloud providers. I already discussed about the complex relationship between cloud providers and LLM providers.
For cloud providers, this DeepSeek efficiency innovation is as welcome as any. Cloud providers were hitting their limits regarding CapEx and the billions investors were willing to approve, especially for training workloads (for inference, nobody is angry as it means revenue). We can see it from the recent Microsoft-OpenAI relationship, where, in essence, Microsoft opted out of committing hundreds of billions of CapEx to help OpenAI grow despite its stake in the company (so OpenAI found Softbank and Oracle to do it).
Similarly, Amazon's AWS strategy with Bedrock was always to host multiple LLM model and have them available for their clients via Bedrock. As I wrote about before in my articles, if open-source LLM models win, AWS wins. Since then, they have hedged their bet to some extent with the investment in Anthropic, but it's still a minority stake, so for them, if an open-source provider wins in the LLM race, they are more than happy (the last thing they want is a God like LLM model, owned by OpenAI or Google, where Azure and GCP are the primary or only cloud providers). Azure's OpenAI exclusive API access was/is a big blow for AWS.
The business of cloud providers thrives when they sell commodities products. Storage, memory, compute. They don't like periods where either Nvidia or an LLM provider has a product that only they have and can, therefore, negotiate the cloud provider into unfavorable relationships from a profit perspective.
The negative for cloud providers is that these smaller models can now run locally or on-prem. This might not be a big deal. Today, only a fraction of IT is run on the cloud (estimates 20-30%), while the rest is on-prem. But even if you have smaller, highly capable models, chances are that once a company sets up its infrastructure to use, say, a DeepSeek R1 model, there will be a new frontier model on the market, and this trend doesn't seem to stop unless scaling laws reach their limits (which so far we have not seen, at least ex pre-training). Companies do not choose cloud providers based on cost-savings, they choose them because it gives them easy to managed capabilities to scale instantly up and down, it is up to date software with constant updates. And especially with LLMs, which are, for an average developer, hard to understand (and increasingly so in the future), not a lot of companies can afford an internal team of ML engineers to update and keep track of their LLM on-prem. Not to mention, once regulations come and you will have to report model capabilities, keep traction of it and its uses, etc., most companies will not want to go through that hassle by themselves but rather have these models hosted in the cloud, and the cloud handling those things for them.
Heavy consumers of AI services
The last segment of companies I want to mention here are heavy consumers of LLMs and GenAI. These are companies like Intuit and Salesforce and social media companies like Meta, Snapchat, and ByteDance.
For these companies, this is a gift. Focusing on social media, social media is a heavy user and will be a heavy user of GenAI, both on the ad side with targeting and hyper-personalized creative generation, as well on the user side, with GenAI content tools and recommendation engine that lift engagement.
For them, getting highly capable models at lower infra costs is a big positive. Snapchat and ByteDance are some of the biggest users of OpenAI models (OpEx), while Meta is investing heavily in CapEx on the infrastructure buildout.
People also mistakenly believe this negatively affects Meta and its Llama efforts. Meta's Llama is an open-source model. Meta's goal all along and the reason why to open-source their model is that they want a future in which an open-source model wins (so they are not dependent on one model provider and, with it, have a lower margin on their core business). The second part was reducing their infrastructure costs with open-source community contributions like this one.
If anything, Meta benefits even more from this DeepSeek situation as the AI community will focus even more on open-source models, away from closed-end ones. But you can be sure that all these innovations from DeepSeek are coming in Meta's new Llama. The ultimate goal for Meta is an affordable and commoditized market of LLMs, similar to what Meta has done with PyTorch.
In the end, for companies like Amazon, Microsoft, Google, and Meta, if the growth of their CapEx slows down to some extent, shareholders will reward this as FCF increases. I think the DeepSeek release might slow down the curve of CapEx for these companies, but I don't think it will cause any company to reduce CapEx. Not to mention, when it comes to AI, it comes down to data and the ecosystem, which all of these companies have.
Summary
The market is filled with individuals with 1st layer thinking and less filled with 2nd and 3nd layer thinkers, it is even less filled with individuals that have domain knowledge to be able to understand the real effects of new tech breakthrough. Because of this, I expect all of the companies that are labeled as »AI« to go through a volatile phase, but at that point for me, as a long-term investor, I am very much ready to add to the names that I find value in and believe will continue to grow as fundamentals won't change but only accelerate with faster AI adoption because of reduced costs.
At the end of the day, companies will adopt DeepSeek changes to improve the models and speed up their process, but having more compute, and more memory will still continue to be the drivers of growth for newer models as long as new frontier models keep scaling and don't reach a wall.
It's important to distinguish that DeepSeek's model is not an innovation in terms of performance. It's an innovation in efficiency.
We are talking about intelligence. The demand for intelligence is unlimited; the only thing that limits the demand for intelligence is the cost of it, which is basically power and compute. If we get breakthroughs like this that lower the cost of intelligence on a compute basis, this only increases the exponential curve that we are on and with it adoption.
DeepSeek, to me, shows us that closed-end LLM providers have cracks in their business models and that VC money might be at risk with funding some of these rounds. The second things is that Nvidia's grip on the market might be reduced to some degree, for all others its something to be cheer about.
Until next time,
If you found this article insightful, I would appreciate it if you could share it with people you know who might find it interesting. Also, consider signing up for my paid plan, where I write even more in-detail pieces on Big Tech and mid/small-cap companies.
Disclaimer:
I own Amazon (AMZN), Google (GOOGL), Microsoft (MSFT), Snapchat (SNAP), Taiwan Semiconductor (TSM), Micron (MU), Sky Hynix and Meta (META) stock.
Nothing contained in this website and newsletter should be understood as investment or financial advice. All investment strategies and investments involve the risk of loss. Past performance does not guarantee future results. Everything written and expressed in this newsletter is only the writer's opinion and should not be considered investment advice. Before investing in anything, know your risk profile and if needed, consult a professional. Nothing on this site should ever be considered advice, research, or an invitation to buy or sell any securities.
Wonderful article Richard!
Smart stuff. Appreciate your explaining. Notable, that AWS margins expanded over the past few years, even with all of the $ spent with NVDA, and scaling up overall AI intiatiives.
Recognize Nvidia integration with CUDA, still hard to see NVDA being able to maintain the same margins as Microsoft, a company that has barely any manufacturing costs.