
Inside the AI Chip Market: NVIDIA, TSMC, Custom ASICs

Hi all,
I am sharing my research findings on the AI semiconductor industry in this article. I analyzed more than 100 interviews from different industry insiders. Former employees from Nvidia, AMD, Amazon's AWS unit, Microsoft, Google, Apple, GlobalFoundries, Qualcomm, Intel, and smaller startup AI semi-companies such as Groq.
For the research, I used interviews found on the leading expert insights library, Alphasense, and interviews I conducted with industry insiders.
I often use bulk analysis of qualitative insights from domain experts because I find their views analyzed in aggregate to be a far more accurate picture of reality than what Wall Street perceives, which is mainly dominated by financial experts.
The date span of this interview was primarily focused on the last 6 months. One of the main reasons for focusing on the last 6 months is that the AI industry is developing so quickly that some older takes might not make much sense anymore.
From the +100 interviews, I narrowed it down to the highest quality insights from 35 experts, based on their employment ranking in the companies and work focus areas. I wanted to have only the highest-quality insights.
The biggest group of the narrowed 35 experts comprises of former Nvidia employees (11).
Now, let’s dive into it.
What are the most common themes that these insiders agree on?
Here are the most frequent topics that overlay from the conversations with them:
CUDA moat
Vertical Integration. It's not just about the GPU.
Importance of custom ASICs: Cost and speed will matter more & Inference
TSM the bottleneck
On edge computing
Nvidia's CUDA
This was one of the most mentioned topic in all of the interviews and discussions.
37% of the experts said that CUDA is a significant competitive advantage. This is generally known by now and is regarded as consensus. With its optimization library, CUDA presents a big hurdle for competitors as most engineers know CUDA and not other languages since it is the language that has been around the longest (since 2006) when it comes to GPU optimization, and it's learned in school. The argument that was often presented was that even tho you do have CUDA converters to other GPU suites like the ROCm (by AMD), the converters don't do a 100% job in converting, so you, as a client, still have a lot of manual work to do with a kernel engineer to convert the code 100%. This presents a friction point for clients, and some experts mentioned that the costs of the kernel engineer manual work + AMD GPU might be higher than just going with NVDA's offer to begin with.
But what I found even more interesting was that 26% of the experts actually said that in some form, especially in the long run, they don't see CUDA as this big barrier that makes competitors unable to compete. There were a few arguments for this take. Firstly, inference workloads are less complex than training and do not require the software stack to be optimized in the same way as with training workloads. Secondly, the competitive advantage becomes smaller because of the CUDA converters; many experts said that a small group of kernel engineers could help program and convert the CUDA code and then integrate it into AI libraries like Pytorch and TensorFlow. The argument is that most developers will be using Pytorch or TensorFlow and won't need kernel engineering knowledge, as a small number of those engineers with open-source contributions can already make the converters fit to help others.
A high-ranking former Nvidia employee:
»Specficially around AI, I don't see a huge hurdle anymore because the number of people that actually are going and writing CUDA or ROCm underneath TensorFlow and PyTorch and doing this stuff, it's actually very small.
Most people are just users of that technology, and so a few people go and solve the problem for everyone, and it's all open source. The entire community is very open-source, very public. Especially on the AMD side, everything is open-source.
If things have advanced to the point where the stuff underneath, it's still very important, but a couple engineers go and do that for everyone.«
source: AlphaSense
Diving deeper into this argument, I looked at the open jobs data for companies and found that the numbers seem to back it up:
Here are the number of job openings that mention NVIDIA’s CUDA as a needed skill. We can see that there has been no significant trend change in the last months and no severe uptick.
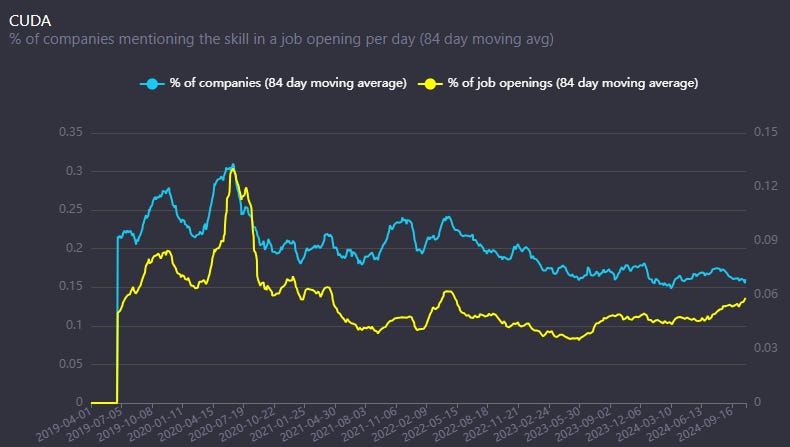
Looking at job openings with Pytorch or TensforFlow as the needed skill, we can see a significant uptick. Companies are looking for engineers who know Pytorch and TensorFlow and, less so, CUDA.


When analyzing, some experts made cases for both arguments, saying that CUDA is a significant advantage in the short-term and will remain for some years, but that in the long run, it will not be such a significant factor as it is today.
An interesting hint about overcoming CUDA was also made by a Former Microsoft director who worked there for more than 20 years:
» I know you do not let another vendor determine your fate in anything. You have to manage it yourself. That's why we partnered with AMD to some extent. It was a backup plan. AMD has proven to be difficult because they had production issues, thermal issues, quality issues, a lot of issues. We overcame that and we also overcame their ROCm API, which was different from CUDA…«
source: AlphaSense
Going through the data, I tend to agree with these findings that CUDA is still a big advantage for NVIDIA in the short term but might not be that critical key piece in the long term as developers are touching up AI higher up the software stack.
Vertical integration is the key
23% of the experts highlighted a more critical part of the NVIDIA advantage/moat: vertical integration.
As this Former High ranking Nvidia employee said:
»The other thing that nobody else is really addressing the same way that I've seen is that NVIDIA no longer sells GPUs when you're talking about training. NVIDIA sells data centers. They're selling you the entire data center with the networking, with the CPU, with the GPU.«
source: AlphaSense
As many experts highlight, the networking Mellanox acquisition made by Nvidia in 2019 was one of the best moves for the company. Mellanox, with its InfiniBand, is a vital piece of the Nvidia puzzle of why the Nvidia training cluster works so well.
Another Former NVIDIA employee said that NVIDIA has optimized its GPUs and networking so that some computation is done directly on networking devices and then moved to the GPUs, making it much more efficient and less power-consuming. He later elaborates that when you use GPUs and networking, you get a 20-25% computation time improvement vs. only using GPUs.
There is also a very good reason why AMD recently acquired ZT Systems. The opinion of these experts here is almost unanimous. AMD did an »acquihire« of ZT Systems. Basically buying the company because they get 1000 systems engineers to help them compete with NVIDIA to get things vertically integrated with clients.
Custom ASICc & Inference
Moving to the topic of custom ASICs. Again, the number here is high, with 29% of the experts discussing custom ASICs as the future, especially for inference workloads. With custom ASISc, the experts refer to these as chips designed by hyperscalers like Google, Amazon, Microsoft, Meta, and »startup« AI chip companies mainly specialized in Inference like Groq, Samba Nova, and Cerebras.
The argument is the following: as inference workloads grow with more usage and scaling (o1 model), it becomes more about speed and costs. Because inference workloads are not as complex as training workloads, NVIDIA's competition is more significant.
As this Former NVIDIA employee said:
» There's these 10 companies and then there's everyone else. These 10 companies with blank checks are going to continue to buy NVIDIA chips.
The other world is, »Okay, how many tokens per second do I get for a dollar? I don't care what the hardware is, I don't care about the software stack. I have a model. I need you to run it in the cloud«. That's the everyone else besides those 10 companies.«
source: AlphaSense
Another Former NVIDIA employee agreed with that take, saying:
»As we talk about inference, inference really doesn't care what hardware is underneath. It's just the tokens per second question. Tokens per second per dollar. That's all that matters. The accountants will decide where you deploy it, not the engineers. That's the situation«.
source: Alphasense
As I had a recent interview with Sunny Madra, General Manager at GroqCloud, their Groq chip right now has faster inference speed and lower cost than Nvidia and is made with 14nm technology. They are now moving to 4nm tech, which will become even more competitive. He also agrees with the take about tokens per second per dollar.
Regarding hyperscaler custom ASICs, the experts believe that Google has the best and most mature offering with its TPUs, followed by Amazon and then Microsoft, which just recently entered the chip design space. A Former Google high-ranking employee working on AI/ML explains that Google started working on their TPUs in 2011-2012 when they experimented with NVIDIA's state-of-the-art GPU and found that while it was performant, it was prohibitively expensive from a cost-per-query perspective.
Still, when it comes to custom ASICs, cloud companies will have to approach this by offering services run on their ASICs underneath. As we already talked about today, the reason is that because these custom ASICs don't run on NVIDIA's CUDA, the hyperscalers will have to do the optimization in-house and just offer services, as nobody knows how to program in non-CUDA languages. Removing all the optimization work for customers and just offering a service is critical, in my view.
Partnership
In my research process I often use the AlphaSense library of over 300M documents from over 10.000 sources. I particularly focus on expert interview with Former employees, big customers and competitors. A lot of really valuable insights can be found there. In partnership with them, you can use this link to get a 14-day free trial. With the free trial, you get access to their whole library of content and can even download expert interviews and other documents.
For all those that use this link to sign up you will also get the 3 most insightful full interviews that I used for this research sent to your email:

Taiwan Semiconductor
Another topic that got high mentions in the interviews was Taiwan Semiconductor (TSMC). 29% of the experts find TSMC one of the most critical companies in the whole AI semi-space, and 23% see TSMC as a bottleneck.
The problem is that all roads lead to TSMC. They are NVIDIA's manufacturer of chips; they manufacture chips for hyperscalers and many AI-specialized startups. The problem is that while you still have other foundries for leading-edge chips like Samsung, it seems TSMC has gotten an even bigger lead in the last few years.
A former Intel employee who worked in the industry for +30 years said the following regarding the competitive space of TSMC and others:
»NVIDIA went to Samsung. Like I said, one is they weren't top dog at TSMC anymore. There were some products that didn't quite materialize at TSMC just because they got deprioritized. Also, TSMC started going reservation-based capacity where you have to prepay. NVIDIA didn't like that so much.
About two years ago when the market went soft, NVIDIA was trying to rearrange that prepaid contract with TSMC, and TSMC strong-armed them and said, "Nope, a deal's a deal, let's take our pay. You go fill us before you fill the other guys. We know that their yield isn't that good." They were right. The yields at Samsung have not been very good for Qualcomm or for NVIDIA.
As a result of that, what's happened is that people late in the game were scrambling back to TSMC asking for additional capacity. That's how TSMC knows where they really stand. You can't make enough parts for your launch window and come begging. That's how they know how the competition is doing. TSMC punished NVIDIA for it a bit. That's no surprise. They also punished Qualcomm a bit.
… NVIDIA's gotten more and more frustrated within Samsung because they can't deliver the consistency of the chips and the yield.«
source: AlphaSense
Many experts think we might see manufacturing supply problems similar to those we had in the COVID era for high-end AI chips. In that kind of event, NVIDIA and Apple will probably be the first in line to get chips from TSMC, as they are their best customers.
A former employee at one of TSMC's competitors - GlobalFoundries, explained well how TSMC determines who gets their orders filled when supply is limited. When TSMC can't meet the demands of its leading-edge node, the way they distribute the capacity between clients is firstly based on contract conditions, but secondly, looking at who can give better prices and higher volumes for future contracts and giving them more of their order filled.
The most common advantages of TSMC emphasized by these interviews are cost control, yield ramp-up, and talent. The smartest people in Taiwan go into hardware development; in the US, it is more about software. So, TSMC has a better pool of talent. TSMC is also attracting talent from all over Asia. The work culture and life-work balance are also different than in the West.
It is also very telling that OpenAI's CEO Altman, at the start of this year, started seeking trillions to build their own AI chip fabs, but now, as reported yesterday, decided to abandon that plan and instead focus just on in-house chip design. Again, the partner they chose for the fab/manufacturing part is none other than TSMC, which again emphasizes just how hard the fab business is and how hard it is to come even close to TSMC.
Interestingly, looking at TSMC’s stock price ( up over 90% YTD), it seems the market has finally figured that TSMC holds a powerful and monopolistic position in this whole AI supply chain.
Looking at the recent segment breakdown of revenues for TSMC – high-performance computing is just starting to pick up. With the substantial growth of Inference just around the corner, their position looks really good (PS: biased shareholder).

On edge
Surprisingly, few experts mentioned on-edge as an important part of the future. Only 14% of the experts discussed on-edge and a smartphone/PC supercycle because of AI. The views here are also not that coherent.
This Former Nvidia employee talked about how he does see a smartphone upgrade cycle but not a PC one:
»From the PC perspective, nobody's PC is powerful enough to do anything meaningful on PC. You're going to go hit the cloud anyway…It makes so much sense for anything to hand it off to the cloud. «
source: AlphaSense
On the other hand, a current Microsoft employee thinks the PC industry will start to add a neural processor unit (NPU) to free up the GPU and CPU. He also believes 25-55% of all PC shipments will be AI-enabled PCs a year from now.
The ones that talk about on edge mostly see it as a mix of SLMs or some kind of compressed models running on edge and then LLMs in the cloud, and this experiences mixing based on the type of model you need for your specific use case. However, this is only for inference workloads.
Summary
Having this kind of discussions and seeing insights from people that actually work in this field at different companies gives me as a researcher a better understanding of what is the reality and what is fiction. I hope you found this as insightful as I have.
Until next time,
Disclaimer:
I own Meta (META), TSMC (TSM), Amazon (AMZN), Microsoft (MSFT) stock.
Nothing contained in this website and newsletter should be understood as investment or financial advice. All investment strategies and investments involve the risk of loss. Past performance does not guarantee future results. Everything written and expressed in this newsletter is only the writer's opinion and should not be considered investment advice. Before investing in anything, know your risk profile and if needed, consult a professional. Nothing on this site should ever be considered advice, research, or an invitation to buy or sell any securities.
Love it, thank you for sharing 🙏
Hi Rihard - Great summary with good insight, as always!
TSMC will also raise prices this years, which means, there is a lot of revenue growth in the current installed base, before new capacity comes online. They have also reported higher than expected yields in their US fabs, which was also not part of the base case for many investors (like me).